










【小白教程】基于树莓派的智能语音助手-python_Python_【小白教程】基于树莓派的智能语音助手-python-CSDN博客
【完整教程零基础】基于树莓派的智能语音助手-python
- 树莓派3b+、python3系统自带、百度语音识别与合成、调用图灵机器人(热词唤醒失败,可用snowboy)
- 1.Windows系统下【下载+安装 树莓派官方系统】
- 2.安装配置pyaudio+snowboy
- 3.百度语音识别 API 及代码实现
- 4.接入图灵机器人
树莓派3b+、python3系统自带、百度语音识别与合成、调用图灵机器人(热词唤醒失败,可用snowboy)
1.Windows系统下【下载+安装 树莓派官方系统】
主要流程:树莓派官网下载系统→刷入 TF 卡→设置开启显示器和 SSH→通电→进入系统
1.Windows下 进入官方网站下载系统镜像:https://www.raspberrypi.org/downloads/
选择右边的版本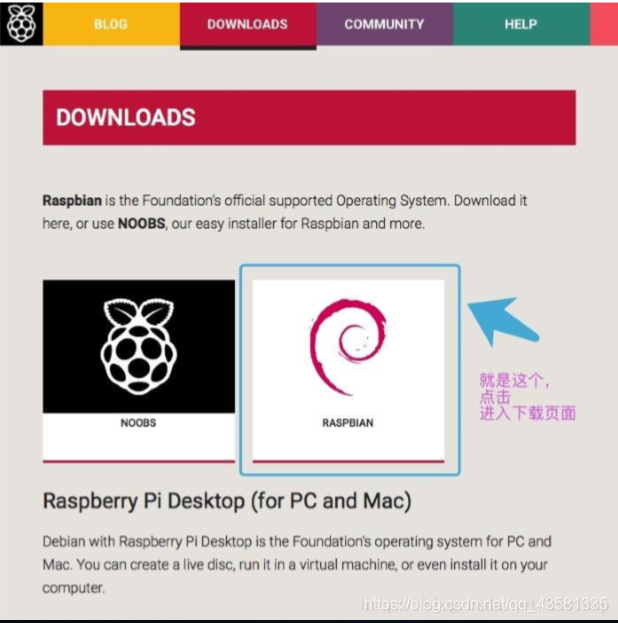
选择左边的版本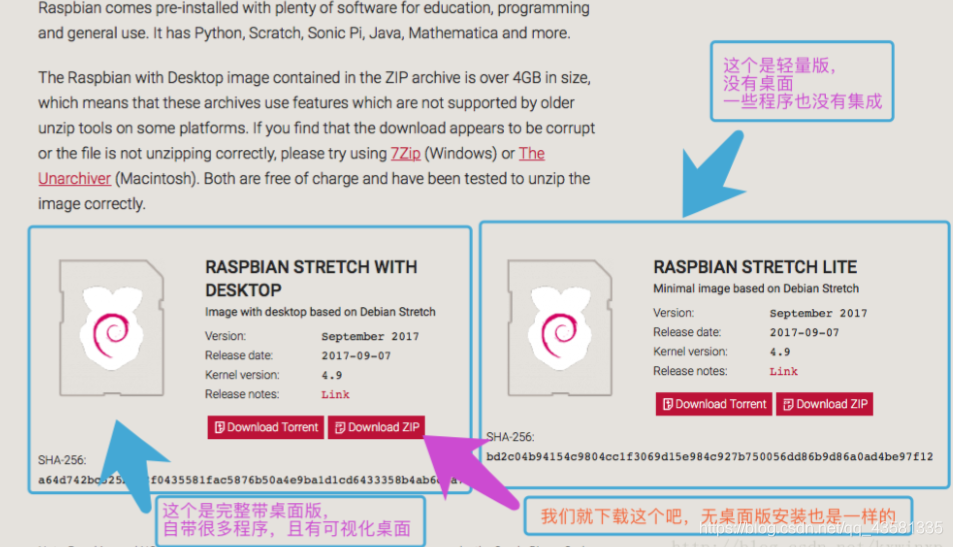 2. Windows系统下的安装
2. Windows系统下的安装
1)首先将准备好的 TF 卡连接读卡器,插入电脑
2)下载一个格式化 SD 卡的工具,格式化 SD 卡
下载网址:https://www.sdcard.org/downloads/formatter_4/eula_windows/ (点击 Aceept 开始下载)
3)下载 Win32 DiskImager,这是一个把镜像写入 SD 卡的工具
下载网址:http://sourceforge.net/projects/win32diskimager/
选择 raspberry.img 系统镜像包,然后选择 TF 卡,点击 Write 即将树莓派系统写入SD卡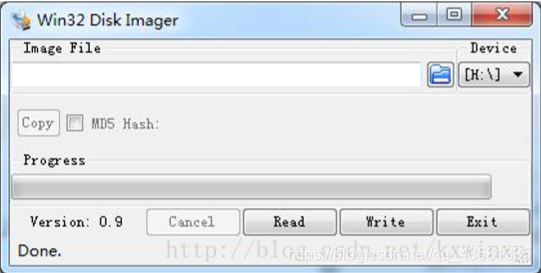
4)对 TF 卡数据进行预设置
a. 开启 SSH 远程:(自 2016 年 9 月开始,raspberry 默认关闭 ssh 连接)
在 TF 卡分区里面创建一个名为 “ssh” 空文件即可(不要有 txt 后缀!)
b. 开启强制 HDMI 输出:(很多现在的显示器在树莓派上并不能识别)
在 TF 卡分区,打开 config.txt 文件(开机后位置: /boot/config.txt),修改如下:
config_hdmi_boost=4 #开启热插拔
hdmi_mode=58 #分辨率为适应屏幕分辨率的选择
hdmi_group=2 # 1:CEA 电视显示器 2:DMT 电脑显示器
disable_overscan=1#可以去掉开机屏幕周围的黑色边框
dtparam=audio=on
c.设置无线 WI-FI 连接:
在 TF 卡的 boot 分区,创建 wpa_supplicant.conf 文件,加入如下内容:
country=CN ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1
network={ ssid=“wifiname” psk=“wifipassword” priority=1 }
d. 插上显示器、键盘、鼠标,上电
在基本的设置完成后,我们将 TF 卡插入树莓派,接上HDMI线连上显示器,鼠标,键盘,上电,即可进入操作界面,如下: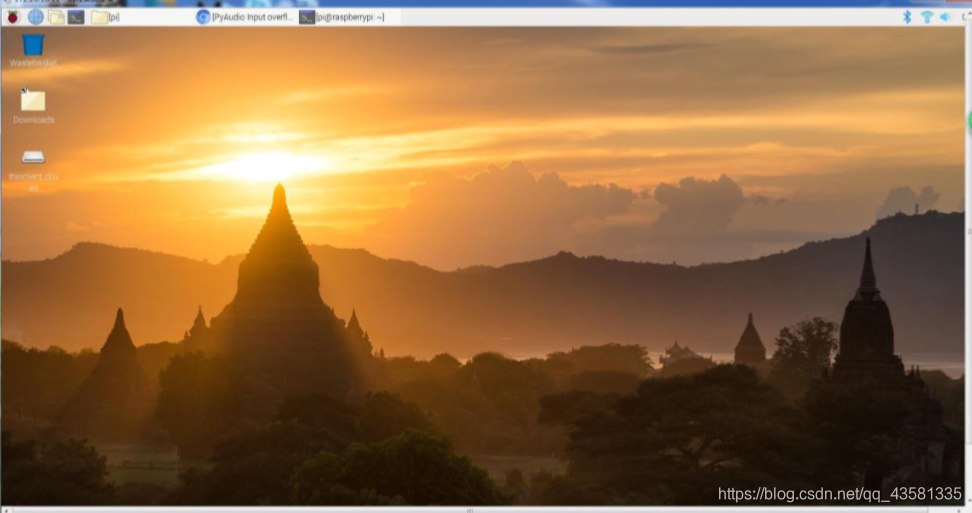
到目前为止,系统就装好了,整个系统下载,安装的过程,我们小组遇到很多奇怪的问题。例如:WiFi连接不稳定,自动断开;进不去系统等等,我们的百度的解决办法,写config文件等,都尝试过,但仍然治标不治本!!!因此,我们采取的简单粗暴的方式——重装系统(很多次)!!!
2.安装配置pyaudio+snowboy
这个很简单,参考树莓派3B+指南(十一)安装配置snowboy. 注意:百度语音采样率为16000。
进行测试播放 wave 文件的实例
#引入库
import wave
import pyaudio
#定义数据流块
chunk = 1024
f = wave.open(r"a.wav","rb") #只读方式打开 wav 文件
p = pyaudio.PyAudio() #打开数据流
stream = p.open(format = p.get_format_from_width(f.getsampwidth()),
channels = f.getnchannels(),
rate = f.getframerate(),
output = True #读取数据
data = f.readframes(chunk)
#播放
while data !="":
stream.write(data)
data = f.readframes(chunk)
#停止数据流
stream.stop_stream()
stream.close()
#关闭 PyAudio
p.terminate()
录音实例:
#引入库
import wave
import pyaudio
#参数定义
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 44100
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "a.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
3.百度语音识别 API 及代码实现
首先需要注册百度语音识别开发者账号,如下: 其次,代码实现如下:
其次,代码实现如下:
# 导入 AipSpeech AipSpeech 是语音识别的 Python SDK 客户端
from aip import AipSpeech
import os
''' 你的 APPID AK SK 参数在申请的百度云语音服务的控制台查看'''
APP_ID = '114xxxx5'
API_KEY = 'NYIvd23qqGAZxxxxxxxxxxxxxxx'
SECRET_KEY = 'DcQWQ9Hxxxxxxxxxxxxxxxxxxxxxx'
# 新建一个 AipSpeech
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath): #filePath 待读取文件名
with open(filePath, 'rb') as fp:
return fp.read()
def stt(filename): # 语音识别
# 识别本地文件
result = client.asr(get_file_content(filename),
'wav',
16000,
{'dev_pid': 1536,} # dev_pid 参数表示识别的语 言类型 1536 表示普通话
)
print result
# 解析返回值,打印语音识别的结果
if result['err_msg']=='success.':
word = result['result'][0].encode('utf-8') # utf-8 编码
if word!='':
if word[len(word)-3:len(word)]==',':
print word[0:len(word)-3]
with open('demo.txt','w') as f:
f.write(word[0:len(word)-3])
f.close()
else:
print (word.decode('utf-8').encode('gbk'))
with open('demo.txt','w') as f:
f.write(word)
f.close()
else:
print "音频文件不存在或格式错误"
else:
print "错误"
# main 函数 识别本地录音文件 yahboom.wav
if __name__ == '__main__':
stt('test.wav')
4.接入图灵机器人
首先,创建一个图灵机器人,如下: 注意,密钥要保持如下隐藏状态:
注意,密钥要保持如下隐藏状态:
测试判断图灵机器人是否调用成功
# -*- coding: utf-8 -*-
import urllib
import json
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
if __name__ == '__main__':
key = '你的 api key'
api = 'http://www.tuling123.com/openapi/api?key=' + key + '&
info='
while True:
info = raw_input('我: ')
request = api + info
response = getHtml(request)
dic_json = json.loads(response)
print '机器人: '.decode('utf-8') + dic_json['text']|
图灵机器人调用的代码:
def AskTuling(tuling_api, tuling_key, content1):
text_input = content1
req = {
"perception":
{
"inputText":
{
"text": text_input
},
"selfInfo":
{
"location":
{
"city": "徐州",
"province": "江苏",
"street": "大学路"
}
}
},
"userInfo":
{
"apiKey": "d4c739c4b5b7422ab15dcc286b8b6734",
"userId": "123"
}
}
# 将字典格式的 req 转为 utf8 编码的字符串
req = json.dumps(req,cls=MyEncoder,indent=4).encode('utf8')
print('\n' + '正在调用图灵机器人 API...')
http_post = urllib.request.Request(tuling_api, data=req, headers={'content-type': 'application/json'})
response = urllib.request.urlopen(http_post)
print('得到回答,输出为字典格式:')
response_str = response.read().decode('utf8')
response_dic = json.loads(response_str)
intent_code = response_dic['intent']['code']
# 返回网页类的输出方式
if(intent_code == 10023):
results_url = response_dic['results'][0]['values']['url']
results_text = response_dic['results'][1]['values']['text']
answer = {"code": intent_code, "text": results_text, "url":results_url}
print(answer)
return(results_text)
# 一般的输出方式
else:
results_text = response_dic['results'][0]['values']['text']
answer = {"code": intent_code, "text": results_text}
print(answer)
return(results_text)
if __name__ == '__main__':
while True:
record_to_file('demo.wav')
voice_text = baiduASR()
print ('voice_text:', voice_text)
answer_text = AskTuling(TULING_API, TULING_KEY, voice_text)
if baiduTTS(answer_text):
os.system("cvlc --play-and-exit %s" % BAIDU_TTS_MP3) 原文链接:https://blog.csdn.net/qq_43581335/article/details/96433550
叨叨几句... NOTHING